Introduction
Being a professional does not mean simply having a degree or completing a credentialing process. Rather a professional is being a part of symbolic community where language functions largely in recurrent activities to exchange and also develop meanings. Meanings could take on such dimensions as ideological, social, cognitive, and logistic. Professional discourse is defined as “any semiotic forms - spoken, written or visual – constituted by and constitutive of social and domain-specific contexts, and used by professionals with special training in order to achieve transactional and interactional, as well as socialization and normative, functions” (Kong, 2014, p. 3). Therefore, understanding characteristics of professional discourse in a particular context sheds insight into roles, identity, and knowledge the profession embraces.This study takes note of unique positions in the education field in Michigan: on-site mentors for K-12 online learners and early literacy (EL) coaches for elementary school teachers. Both professional groups have been formulated based on Michigan’s legislative (Michigan Public Act § No. 249, 2016) or educational policy[1] actions to improve statewide education. Educational legislative and policy endeavors both require a feedback loop in order to increase the clarity in policy messages and the specificity for program implementation (Porter, Floden, Freeman, Schmidt, & Schwille, 1988; Porter, 1994). To this end, the present study is to probe discourses of those two unique educational professional groups.Since knowledge and discourse or language are related to one another in reciprocal fashion: knowledge shapes discourse and language plays a role in knowledge development, professional discourse research could offer an answer to questions of what kind of knowledge is important in those two professional groups and what is the role of discourse in acquiring and representing professional knowledge. Furthermore, given that all components of meaning, practice, community, and identity are deeply interconnected (Wenger, 1998), understanding professional discourse offers a space for projection of professional identity development. Study findings will ultimately provide an answer to the question of how we support those educators.Data of professional discourse can be collected in various ways, and this study is based on written language in discussion forums of two virtual professional communities (VPC). Mentor Network was designed and provided for on-site mentors whose primary role was academically advising students who take online courses. EL Coach Network was for educators who committed to working with elementary school teachers throughout Michigan. Taken all together, the discourse in question is written format of language, falls under the category of intraprofessional discourse, and the community context is specifically an online platform. Discussion in this report will center around methods to analyze professional discourse and bring together three methods: (a) text-mining focused on content words; (b) text-mining focused on function words; and (c) social network analysis.
Method
At the time of data collection (September 30, 2018), Mentor Network had 242 enrolled members and the EL Coach Network had 1,147, each of which included 186 and 694 members who participated in professional discourse activities by posting on either introduction or discussion boards. Yet, we limited the study sample to discourses captured by threads to discuss about specific educational topics by excluding data from introduction boards. This procedure returned the study sample of 19 of Mentor Network and 78 of EL Coach Network.Since the purpose of this report was to illustrate three types of analytic approaches in delving into professional discourse, the following section for results will present information on data format and analysis procedures in more detail. Accordingly this method section will be devoted to a brief description of original source of data and data preparation for proposed approaches.The original source of data was threads in discussion forums for text-mining and members’ connections with one another as well as particular thread topics (i.e., a connection between a member who initially posted and another member who responded it around a particular topic) for social network analysis. So raw data sets were developed in the form of corpora in text file and matrix in a spreadsheet file.Specifically, the study sample contained texts and network matrices from the Mentor Network participants who interacted with one another around six topic areas through 42 threads that contained a total of 183 postings. Six topic strands were: (a) General ideas and questions, (b) Starting a new term strongly, (c) Annual mentoring calendar, (d) Public knowledge base, (e) Credit recovery, and (f) Fully online programs. On average, a thread was formed with 4.4 responses to the initial post, with a minimum of zero (13 threads) and a maximum of 22. Those 13 threads that had received no response from colleagues were to cover discussion about particular program formats of online learning (e.g., credit recovery and full-time online learning) whereas actively engaged topics area focused on the mentor role or instructional practices in general.EL Coach Network had a unique design feature in the VPC, curating predetermined contents for professional learning, Essentials in addition to the general discussion forum. Participants were expected to use those predetermined contents as anchors in their discourse. As a result, the number of topic areas in total was greater than the Mentor Network. General discussion forum brought together discussion strands including (a) Free Discussion, (b) Interacting with Administrators, (c) 3rd Grade Reading Law and Assessment, (d) Grant Opportunity; (e) A Place for New Coach to Share. Within the discussion forum for Essentials, members were able to discuss about for instance, (a) Deliberate research-informed efforts to foster literacy motivation and engagement within and across lessons, (b) Small groups and Individual instruction, using a variety grouping strategies, most often with flexible groups formed and instruction targeted to children’s observed and assessed needs in specific aspects of literacy development, and (c) An ambitious summer reading initiative supports reading growth.From both discussion forums, 84 threads with 304 postings were collected, which included 26 only-one-posting threads that did not obtain colleagues’ replies. A close observation of those threads called our attention to that members lost opportunities that would have promoted rich discourse and in turn, collective learning. For instance, some threads that explicitly sought for resources recommendation/advice feedback, other districts’ experience to share, and colleagues’ reflection upon particular materials were not extended by colleagues’ responses to initial postings.
Results
Method 1. Text-mining to investigate focal points in the discussion
The discussion forum was a useful source of text data for characterizing a professional community, and one way of doing it was text-mining focused on topic areas that were associated with persisting involvement of many participants. This type of text-mining primarily used content words in corpus. By probing frequency of content words and correlation between two words, what the community members communicated about was identified, and we were able to better understand their focal points in the professional discourse.The first step was to extract the text from a collection of threads. Text scraping can use commercial software (e.g., Outwit) or programming languages such as Python or Java, but it can also be done manually, i.e., copying and pasting texts from webpages into a document file. The outcomes from the analysis were then summarized by a word cloud as a visual representation of the most frequently uttered words. Resultant key words and their correlated words then guided us to explore focal points in the discussion through the thematic analysis (Ignatow & Mihalcea, 2017).An infrastructure offered in R—tm package (Feinerer, 2018) allowed for this type of text-mining. See http://www.rdatamining.com/examples/text-mining[2] for R program codes. Processes of tokenization, stop-word removal, and stemming were followed by the primary analysis--calculating frequencies of and correlation among words. Tokenization was to separate the punctuation marks from the text and to identify contractions or abbreviations. Since the first method turned its attention to content words, stop words and other function words such as pronouns, articles, and prepositions, were removed prior to the main analysis. However, the function word is useful to serve other purposes of research, for instance, psycho-linguistic characteristics of language usage, which will be presented in the section of the second method. The final step of data processing in R was stemming for words sharing similar meanings but being in different surface forms, for example teacher, taught, teaching, and so on.As the main step, the data set containing only content words were then summarized with the frequency of utterance of each word and list of highly correlated word pairs. Those quantifiable measures were a foundational tool for identifying themes as focal points for particular educator groups. Since the thematic analysis was not a linear process, the study team needed to move back and forth from the text-mining summary report to the entire corpus along with the theoretical and/or conceptual framework, reading the texts carefully, and taking notes extensively (Braun & Clarke, 2013). When followed by those qualitative analytic approaches, the present method was able to identify the focal points in the community. And the results of Method 1 follow:Mentor Network

EL Coach Network—General Topics
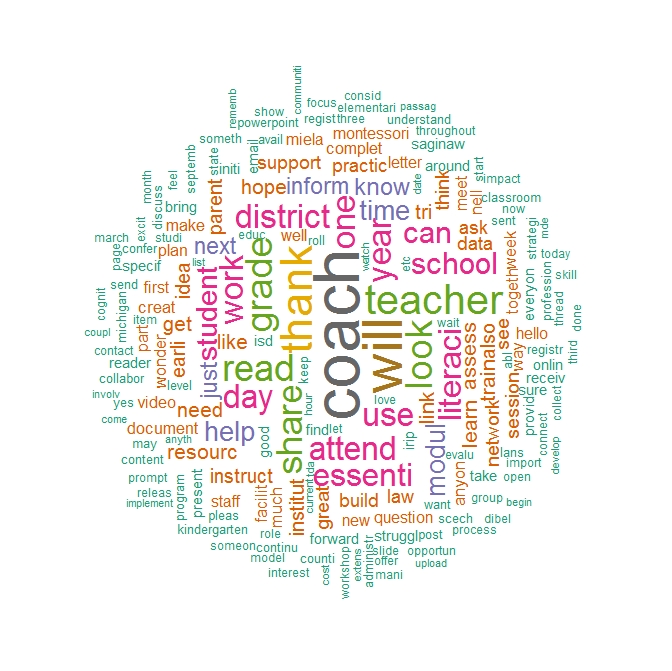
EL Coach Network—Curated Contents
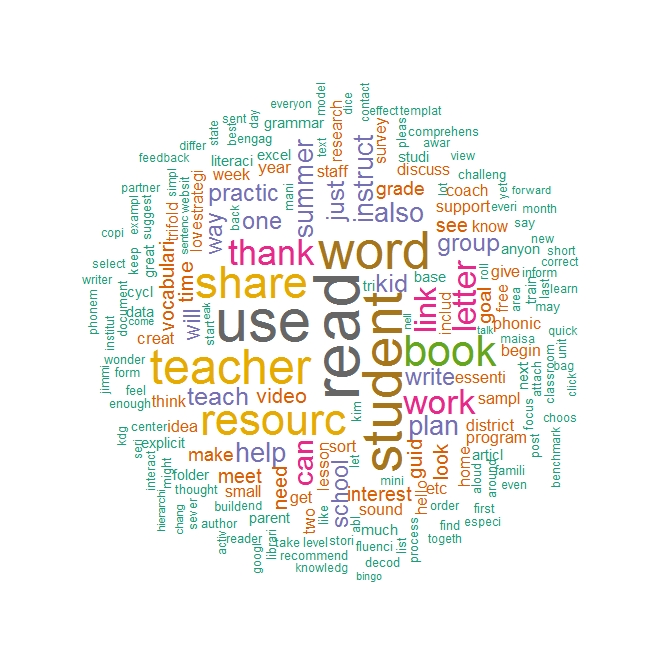
Figure 1. Word-Cloud.Figure 1 presents the three word-clouds. The first word-cloud is for Mentor Network members, and indicates “student,” “online,” and “course” as the most important words in discourses. Text extracts were collated with the conceptual framework (see Kwon & DeBruler [2019] for the conceptual framework used), leading a conclusion that to mentors, as shown in their primary role--advising students who take online courses at the school building, the theme of student learning and/or change emerged as a focal point in their professional discourse.More specifically, those education professionals appear to engage in discursive activities regarding:
Powerful avenues to success in the online-learning environment, and
Effective ways to intervene if a student fell behind in a course.
There was an example in which the usefulness of correlated words stood out in the thematic analysis. One of key words, “mentor” reportedly had highly correlated words, “amount,” “golden,” and “maximum.” With those words, conversations were shaped regrading mentors’ caseloads, duties, and commitments. But participants appear to reflect upon various school contexts rather than to seek for “a golden number.” The study team’s discussion for the thematic analysis related those findings with how professional identities were developed in the education professional’s discourse, revealing out that educators’ discourses regarding professional identities tended to pan out considering the local social context of schools.The second word-cloud reports key words from corpora in EL Coach Network’s general discussion forums. The following analysis for the word, “coach” revealed that conversations were geared toward specific pedagogical change. Specifically, early literacy coaches’ persisting engagement with discursive activities stood out in the following topics:
How to collect and use student achievement data in literacy instruction, and
How to collect teacher data in terms of instructional practices.
Other key words, “will” and its closely related terms such as “share,” “collaborate,” “reach out to,” and “willing to” guided the study team to justify collegiality and/or shared leadership exhibited by the community. The word of “thank” appears to communicate the appreciation expression in between those collaborative interactions.The last word cloud is for forums about pre-curated contents provided by the community developer for EL Network members. In corpora containing the keyword “read,” it has been found that “read” was used for two different contexts: student reading (e.g., sharing reading activity resources) and educator reading (e.g., reading materials for professional development). Themes emerged regarding knowledge development and collective learning and hence provided evidential support for the usefulness of curated learning materials serving as an anchor helping those processes. Education professionals exercised the collective intelligence while using such phrases as:
“One way to think about”
“I would love to chat about”
“Does anyone have any other”
Method 2. Text-mining to examine psycho-linguistic characteristics of discourse
The second method of text mining focused on function words such as pronouns, prepositions, and conjunctions. Exploring those words enabled understanding of another aspect of discourse--social and/or psychological characteristics in the discourse (Tausczik & Pennebaker, 2010). Pennebaker’s team developed Linguistic Inquiry and Word Count (LIWC), a computerized text analysis program. The analysis was based on the program’s key feature referred to as “dictionary” that was composed of almost 6,400 words. Each word was tagged by one or more categories, and LIWC summarized a corpus based on those categories in the dictionary for its LIWC psycho-linguistical characteristics (Pennebaker, Boyd, Jordan, & Blackburn, 2015).Among approximately 90 variables that are generated by LIWC, foundational characteristics of corpora were informed by such variables as word count (hereafter WC), word count per sentence (WCPS), percent of target words included in the dictionary (Dictionary), and percent of words that are greater than six letters in length (WC>6 letters). Other categories including articles, prepositions, pronoun, auxiliary verb, conjunction, adverb, and negation is viewed as a proxy of analytic process behind word usages (Pennebaker, Chung, Frazee, Lavergne, & Beaver, 2014). In particular, the LIWC’s summary variables provided useful information for the four types of linguistic characteristics of discourse: (a) analytical thinking (Analytic), (b) clout (Clout), (c) authenticity (Authentic), and (d) emotional tone (Tone) in the language usage (Pennebaker et al., 2015).Furthermore, other variables focused more on psychological process behind language usages, for instance affective, social, cognitive, perceptual and, biological processes, each of which included sub-categories. The cognitive processes synthesized the psychological aspect of discourse that was captured by such variables as insight (e.g., think, know), causation (e.g., because, effect), discrepancy (e.g., should, would), tentative (e.g., maybe, perhaps), certainty (e.g., always, never), and differentiation (e.g., hasn’t, but, else). We found box-whisker plots useful in visualization to compare the four linguistic summary variables or sub-categories within the cognitive processes.Table 1 presents part of the aforementioned LIWC results. Since LIWC manual (Pennebaker et al., 2015) reports results from analyzing a variety of corpora that were used in developing and validating the program, we could get a sense of the degree to which the certain characteristics emerged more strongly by comparing the study sample with those text samples. For this report, we chose Blog, Twitter, and NY Times samples.Table 1.
Study Sample | Pennebaker et al (2015) Corpus Samples | ||||
|---|---|---|---|---|---|
Mentor (Obs. 19) Mean (Min ~ Max) | EL Coach (Obs. 78) Mean (Min ~Max) | Blog | NY Times | ||
WC | 730.26 (11~ 1800) | 209.27 (2 ~ 2196) | 3206.45 | 660.24 | 744.62 |
WCPS | 15.79 (5.5 ~ 20.29) | 12.95 (1 ~ 23.13) | 18.4 | 12.1 | 21.94 |
Dictionary | 87.81 (76.19 ~ 91.44) | 83.94 (57.14 ~ 100) | 85.79 | 82.6 | 74.62 |
WC>6 | 20.71 (10.68 ~ 25) | 24.99 (0 ~ 57.14) | 14.38 | 15.31 | 23.58 |
Articles | 6.57 (0 ~ 9.62) | 6.01 (0~14.29) | 6 | 5.58 | 9.08 |
Preposition | 14.36 (9.62 ~ 19.05) | 12.36 (0 ~ 21.74) | 12.6 | 11.88 | 14.27 |
Conjunction | 5.12 (0~ 7.77) | 4.76 (0 ~ 14.29) | 6.43 | 4.19 | 4.85 |
? mark | 0.61 (0~ 2.5) | 1.01 (0 ~ 8.33) | 0.59 | 1.4 | 0.15 |
Assent | 0.15 (0 ~ 0.65) | 0.44 (0 ~ 6.82) | 0.33 | 1.82 | 0.05 |
I | 4.07 (0 ~ 9.09) | 3.54 (0 ~ 14.29) | 6.26 | 4.75 | 0.63 |
We | 1.67 (0 ~ 9.09) | 1.91 (0 ~ 10) | 0.91 | 0.74 | 0.38 |
LIWC2015 ResultsOn average, the mentor members’ corpora took in an average of 730 words per person and 16 words per sentence, which is smaller than Pennebaker et al’s two samples of Blog and NY Times. The early literacy coaches’ corpora appear to be even smaller in length as well as in sentence length than three text samples including Twitter. This is explainable by a large number of participants in the EL Coach community, nonetheless, the results imply improvement needs to scaffold richer social and intellectual participation (Booth, 2012; Scott, Clarkson, & McDonough, 2011).According to Tausczik and Pennebaker’s study (2010), proportions of prepositions (e.g., to, with) or conjunctions (e.g., and, also) could be connected with a depth of thinking. In that respect the two corpora were considered as a complexity at a similar degree to either of the Blog or NY Times samples. Categories of question marks or assent-related words (e.g., agree, OK, yes) were of a good evidential use in terms of coordination behaviors and group process in a socio-constructive space among these types of education professionals.Below, other variables on psycho-linguistic summaries are presented in graphical form (Figure 2). The box and whisker diagram enables comparing among subcategories, for instance analytic vs. clout vs. authentic vs. tone within the four linguistic processes. The low panel displays results for six sub-categories of cognitive characteristics and each of the panels include red dots if outliers stand out.Mentor
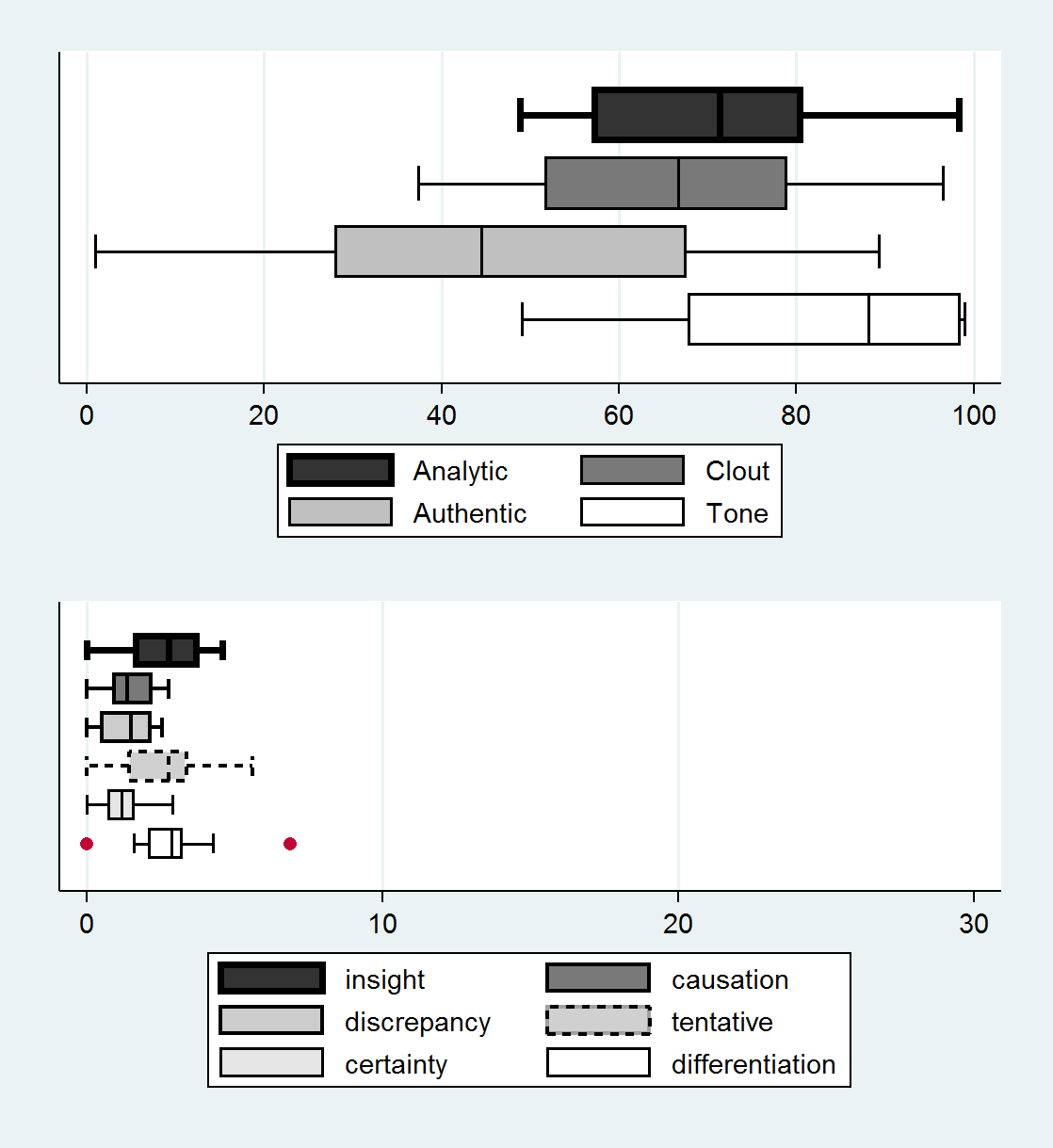
Early Literacy Coach
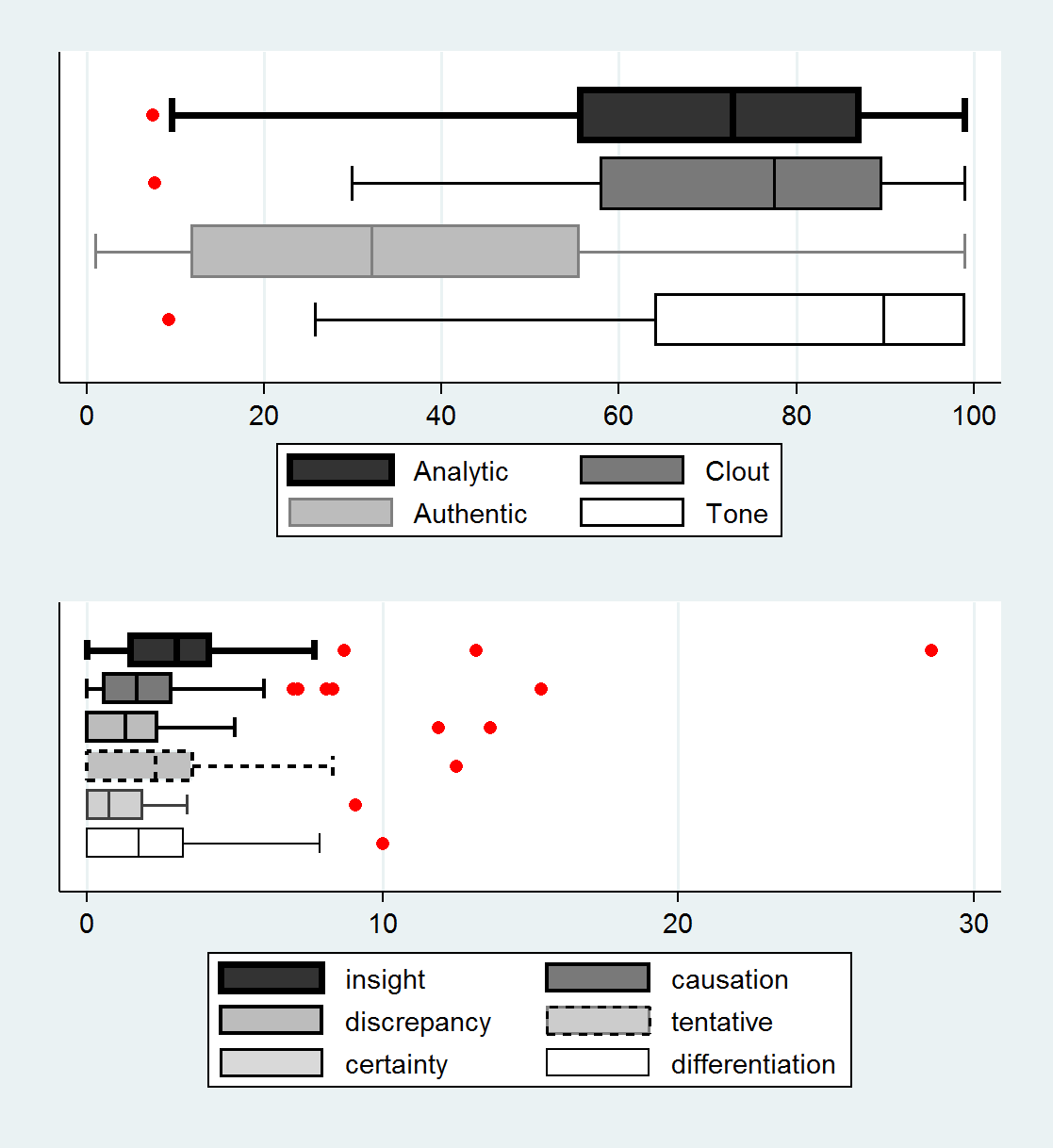
Figure 2. Linguistic and Cognitive Processes.Among the four linguistic summary categories, the emotional tone category stood out in both corpora with the greatest estimate on it. The study team’s revisit of text data revealed out that this finding related to overall emotional positivity: on average there is greater use of positive words (4.37% per person in mentor discourse and 5.13% in early literacy coach discourse) than those of negative words (0.34% and 0.26%). One can conclude that one of the outstanding characteristics of education professionals’ discourse is communicative transactions appreciating shared resources and celebrating collegiality.Note that unlike other variables that report proportions of particular words, the linguistic summary variables were based on an algorithm configuration combining multiple categories of words and standardization process. Referring to other empirical studies that used the LIWC was a practical way of interpreting results. For instance, more use of articles and prepositions and less use of pronoun, auxiliary verb, conjunction, adverb, and negation could constitute “analytic” language use (Pennebaker et al., 2014), whereas the clout dimension could be linked to relatively less use of first-person singular and more use of first-person plural (Kacewicz, Pennebaker, Davis, Jeon, & Graesser, 2014). In concert with that, the study team attempted to explain the results that both text samples indicated the variables of analytic and clout at relatively high degrees and more frequent use of the plural pronoun than any of three LIWC samples, suggesting how a group of education professionals in an online space created a community with the source of coherence, the shared repertoire (Wenger, 1998).The authenticity component, at the lowest among the four linguistic summary variables for both text samples, is plausible given the professional discourse shows a propensity to keep distance narrators from the discourse per se, rather than exchanges of personal and real stories, such as discourses in blogging. This characteristic of professional discourse would feed into the authenticity variable at relatively low rate. Nonetheless, the results calls forth future research needs when the professional discourse is anchored by classroom artifacts, samples, student work, and/or recordings.The second plots in the low panel present results of cognitive sub-categories. For both groups of professionals, it is in the categories of insight, tentative, and differentiation that members used cognitive vocabularies more frequently. The insight category is composed of 259 words including “think” and “know,” the tentative category of 178 words including “maybe” and “perhaps,” and the differentiation category of 81 words such as “but” and “else.” The study team translated those results into the frequent use of “insight” words highlighting the context of sharing various ideas, the use of “tentative” in other words cautious words indicating participant empowerment freely to comment, disagree, or clarify, and the use of “differentiation” words implying meaning shifts to correspond to situation shifts in the professional discourse.
Method 3. Social network analysis for discovering the connectedness among community participants around discussion topics
The third type of data from the discussion forum was network: connections among members who posted and who responded to others’ postings. So the data was processed into a matrix representing who was connected to whom and how many times each connection took place. Since we were interested in how those ties among members were connected to which threads, we included one more dimension in the analysis, which made the network 2-mode data. This design enabled us to explore how actors are connected by communication ties and what communication topics are involved in those connections. UCINET (Borgatti, Everett, & Freeman, 2002) is a computerized program for this social network analysis (SNA). The network data can be analyzed in a variety of ways, including estimating density of the entire network (i.e., the probability that a connection occurs between any pair of randomly chosen participants) and examining the reciprocity between two participants. Focusing on actors, centrality (i.e., a participant’s position in a network) and/or subgroups within the entire network could be examined. One foundational step to analyze social networks is visualization of it in a meaningful way (Borgatti, Everett, & Johnson, 2013).This report presents the process and outcomes of analyzing networks through visualization. A network diagram consists of a set of nodes representing participants and discussion topics and a set of lines representing who is connected to whom and for what discussion topic. One of the most important aspects of network visualization is the position of nodes communicating information about nodes in the center or on the periphery within the network. However, the UCINET’s NetDraw procedure took some optimization algorithms (e.g., equal-length lines), gaining better readability of diagrams at the expense of interpretability (i.e., distance between two nodes in the diagram correspond in the actual distance in the network). The network diagram in this report is communicating sketch information in terms of nodes’ location to denote central or peripheral participants and discussion topics.Embedding additional information in diagram layout could enrich information, that is, it is possible to alter diagram properties by incorporating background information of the actors or social network estimates into it. For this report, the strength of connectedness was used as the node attribute and the size of node was chosen as a visual property. Accordingly, big nodes represent power users and focal points in discourses. Figure 3 and Figure 4 present two social network diagrams of the study for Mentor network and for EL network.
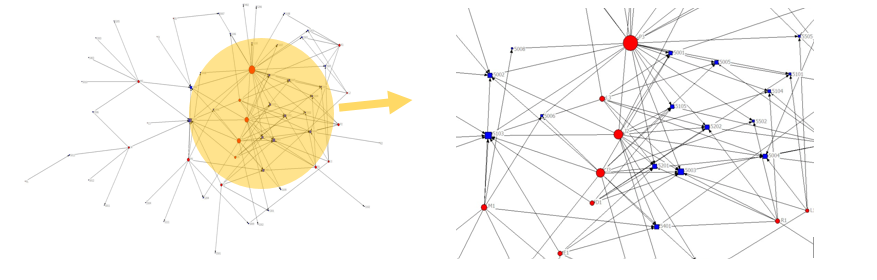
Figure 3. Two-Mode Social Network Diagram of Mentor Network.
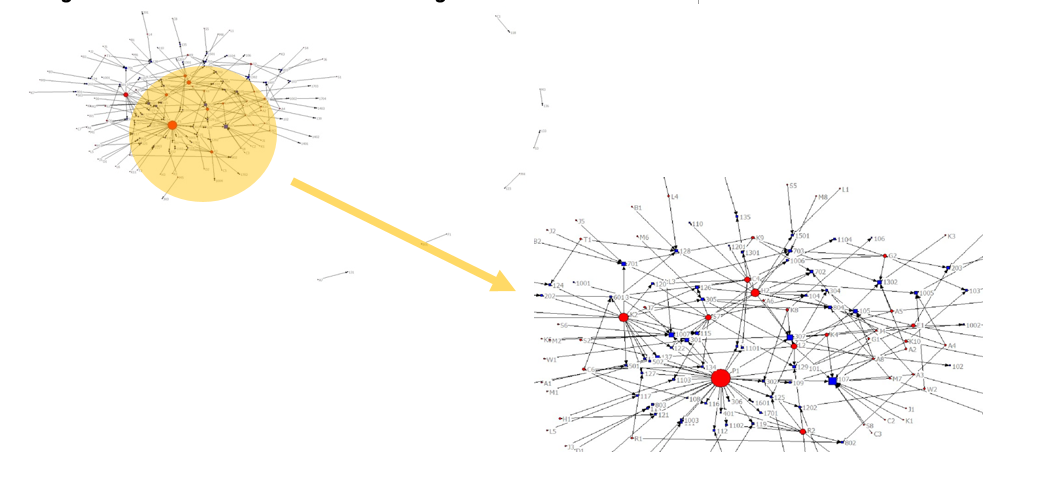
Figure 4. Two-Mode Social Network Diagram of EL Coach Network.Circles in red represent actors who created a post or responded to an initial posting and squares in blue denote postings. Accordingly, both types of nodes in the enlarged part of the network diagram inform who the power users are in the community and in what threads their activities are actively involved. The study team was interested in identifying power users’ behaviors in the professional discourse by relating the SNA results to the original corpora and the facilitating behaviors found were as follow:
Long posting sharing out their own contexts or ideas to initiate a thread
Long posting to extend the existing thread in the midst
Frequent short postings to express agreements or appreciation
Probing questions to elaborate given information in Mentor Network
Posing general questions
Encouraging members’ participation
Actively sharing resources
Expressing positive feedback on colleagues’ activities
Threads through which the power user is connected to peripheral nodes: directing members to existing resources related to question or request
Providing logistical supports for the community management
Discussion
The purpose of study was to understand the dynamic of professional discourse for the two types of education professionals when they were networked by the virtual professional learning community. As a part of the project, this report proposed three methods to organize, summarize, and understand vast quantities of data from discussion forums. The first method, text-mining focused on content words was based upon the assumption that a body of texts were amalgamated by a common focus. So this key word search coupled with thematic analysis could be a useful approach in the design and implementation of a professional community for various educators. The present study found discourses based on practical knowledge elicited collectively reviewed professional knowledge focused on student learning and professional identity for Mentor Network members and on pedagogical change and collegiality for EL Coach Network members.Note that the present study limited its method to exploring texts and topics descriptively. If further and deeper examination focused on discourse topics (meaning in the community, [Wenger, 1998]), topic modeling could be considered to discover hidden topical patterns and/or topic representations per person, for instance Latent Dirichlet Allocation and text rank.The second method, text-mining focused on function words, was useful to summarize the corpus in a new way. The study team chose the four linguistic summary and the categories for the cognitive process to better understand community and identity components within the social theory of learning (Wenger, 1998) and identified characteristics of education professionals’ discourse with communicative transactions appreciating shared resources, celebrating collegiality, bouncing off ideas, and developing professional identity. In particular, the result of Authenticity carried a significant implication--fostering active authoring in terms of aspect of authenticity through improvement in design components, participation policy, and day-to-day practices in the professional community.Lastly, the third method of social network analysis enabled the study team to explore data from discussion forums in a different way. Observing the power users’ discursive behaviors helps specify facilitator roles in professional communities. Furthermore social network analysis provides a variety of network- or person-based measures. For instance, multiple data sources for different networks could be compared through comparing estimates of cohesion (how closely network members are connected) or reciprocity (to what extent a time from one member to another member is matched) between networks.It should be noted that the three methods were used to understand group facets of learning in communicative interactions, but did not focus on individual differences in social and cognitive presence within the process of collective knowledge development. For instance, a node’s position in a network could be explored more deeply by the use of various centrality estimates. Social network analysis also enables research to focus on characterizing subgroups of a network.Any investigation into discourses and social networks that can be attributed to a combination of various internal and external factors is complex and multifaceted. Thus, there are several limitations which will impact upon the interpretations and generalizability of study findings. For example, while this study extracted discourses and network relationships formed through online discussion activity focused on writing behavior, the study did not capture all interactions participants undertook through reading behavior and extra conversations outside of discussion forums. Also, it should be noted that by the nature of three methods, discourse contents and emerging themes from threads that received no response from colleagues were underestimated.
Reference
Booth, S. E. (2012). Cultivating knowledge sharing and trust in online communities for educators. Journal of Educational Computing Research, 47(1), 1-31.Borgatti, S. P., Everett, M. G., and Freeman, L. C. (2002). Ucinet for windows: Software for social network analysis. Harvard, MA: Analytic Technologies.Borgatti, S. P., Everett, M. G., and Johnson, J. C., (2013). Analyzing Social Networks. Sage.Braun, V., & Clarke, V. (2013). Successful qualitative research: A practical guide for beginners. Sage.Cardno, C. (2012). Managing effective relationships in education. Sage.Feinerer, I. (2018). Introduction to the tm Package Text Mining in R. Retrieved from https://cran.r-project.org/web/packages/tm/vignettes/tm.pdfIgnatow, G., & Mihalcea, R. (2017). Text mining: A guidebook for the social sciences. Sage Publications.Kacewicz, E., Pennebaker, J. W., Davis, M., Jeon, M., & Graesser, A. C. (2014). Pronoun use reflects standings in social hierarchies. Journal of Language and Social Psychology, 33, 125-143.Kong, K. (2014). Professional discourse. Cambridge University Press.Kwon, J. & DeBruler, K. (2019). Unpacking Network and Discourse of Educators in Professional Learning Communities. In K. Graziano (Ed.), Proceedings of Society for Information Technology & Teacher Education International Conference (pp. 629-639). Las Vegas, NV, United States: Association for the Advancement of Computing in Education (AACE). Retrieved March 29, 2019 from https://www.learntechlib.org/primary/p/207758/.Michigan Public Act § No. 249. (2016). Retrieved from http://www.legislature.mi.gov/documents/2015-2016/publicact/pdf/2016-PA-0249.pdfPennebaker, J. W., Boyd, R. L., Jordan, K., & Blackburn, K. (2015). The development and psychometric properties of LIWC2015.Pennebaker, J. W., Chung, C. K., Frazee, J., Lavergne, G. M., & Beaver, D. I. (2014). When small words foretell academic success: The case of college admissions essays. PloS one, 9(12), e115844.Porter, A. C. (1994). National standards and school improvement in the 1990s: Issues and promise. American Journal of Education, 102, 421–449.Porter, A. C., Floden, R., Freeman, D., Schmidt, W., & Schwille, J. (1988). Content determinants in elementary school mathematics. In D. Grouws & Thomas Cooney (Eds.), Perspectives on research on effective mathematics teaching. Reston, VA: National Council of Teachers of Mathematics.Scott, A., Clarkson, P., & McDonough, A. (2011). Fostering professional learning communities beyond school boundaries. Australian Journal of Teacher Education, 36(6), Article 5.Tausczik, Y. R., & Pennebaker, J. W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of language and social psychology, 29(1), 24-54.[1] Michigan's Action Plan for Literacy Excellence. (n.d.). Retrieved from https://www.michigan.gov/mde/0,4615,7-140-28753_74161---,00.html[2] RDataMining.com: R and Data Mining: Text Mining. (n.d.). Retrieved from http://www.rdatamining.com/examples/text-mining